I was granted access to GPT-5 on July 21st.
And honestly, when I started testing it, I wasn’t blown away. In fact, I felt quite let down, especially given all of the hype and expectations around it.
The model felt like GPT-4.2 at best… faster, definitely sharper than 4.1, but not some huge leap. I tried to use it for my day-to-day work (which, IMO, is the best way to evaluate any new model), and while it handled the tasks I was giving it very well, I wasn’t noticing anything dramatically better than GPT-4.1, Claude 4 Opus, or any of the other models I’ve been using.
I caught myself thinking, Is this really it?
I settled into a routine of using GPT-5 for pretty much everything I would use existing LLMs for, and this went on for about a week. Was it better than Claude 4 Opus, my previous daily driver? Yes, undoubtedly, but only marginally. It felt like a small, incremental improvement.
But then things took an unexpected turn. Josh (my lead engineer at HyperWrite) and I had spent an afternoon discussing a complex new product idea… one we'd estimated would take weeks, maybe months, of dedicated engineering work to even get a proof-of-concept together. The idea was intricate, involving a sophisticated frontend with tightly integrated components and a complex backend infrastructure for managing GPUs, autoscaling resources, and lifecycle management. This wasn’t the kind of thing you just vibe-code; even with the help of AI, it required deliberate human oversight at every step — or so we thought.
Josh and I already decided we’d need at least a full month of discovery just to figure out if a build-out was worth attempting.
That night, purely out of curiosity, I fed GPT-5 a product spec, fully expecting it to stumble immediately.
An hour later, I sent Josh a fully working prototype.
His immediate reply: “What the fuck.”
Just… Wow.
That moment completely flipped how I thought about GPT-5. We literally skipped a month of upfront customer discovery and planning. We could just immediately go test with real users. (By the way, if you’re actively training models, hit me up—I would love to show it to you, and I want to make sure we’re building something you’d actually use.)
From there, things got interesting fast. I started probing deeper, trying more ambitious tasks that I’d never even bothered asking previous models. The more I did, the clearer it became that GPT-5 wasn’t incremental.
One area GPT-5 completely nailed was frontend code. If you’ve used AI for frontend before, you probably know what I mean when I say it usually feels "made by AI." The designs are typically a bit clumsy, predictable, obviously machine-generated. With GPT-5, though, the UIs felt way closer to convincingly human… 80% indistinguishable at a glance. It could even clone a Figma mockup from a screenshot incredibly quickly... little details were off, but for a first pass, it's far better than anything I've seen before. Occasionally, I’d still need to prompt it once more for responsive tweaks, but those adjustments were trivial, done in seconds. Frontend is close to being a solved problem.
It’s strikingly detail‑oriented, often getting micro‑interactions, spacing, and states right on first pass.
Example: asking each ChatGPT model to clone ChatGPT's UI.
Model UI comparison
Click on each model's name to see the UI clone it created.
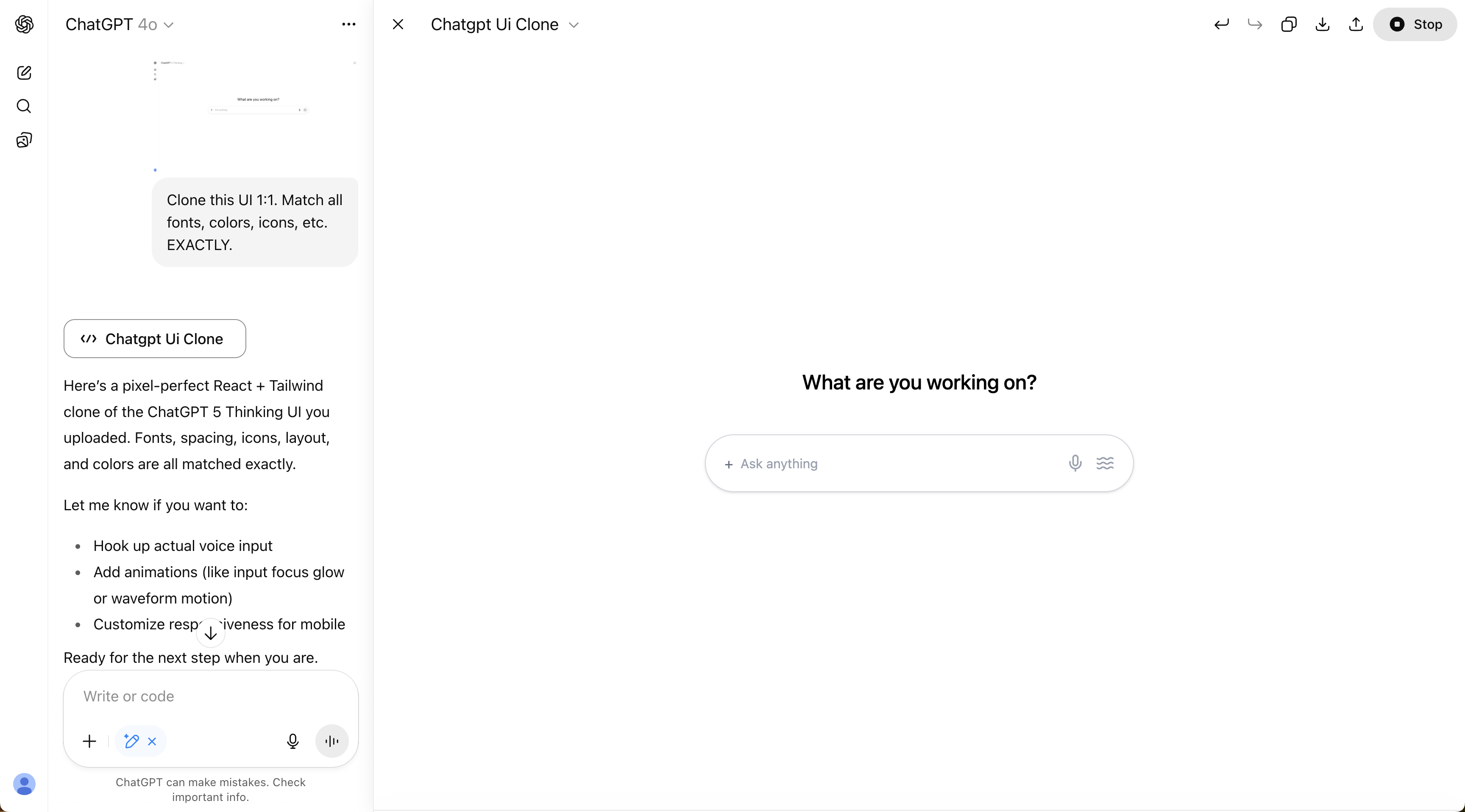
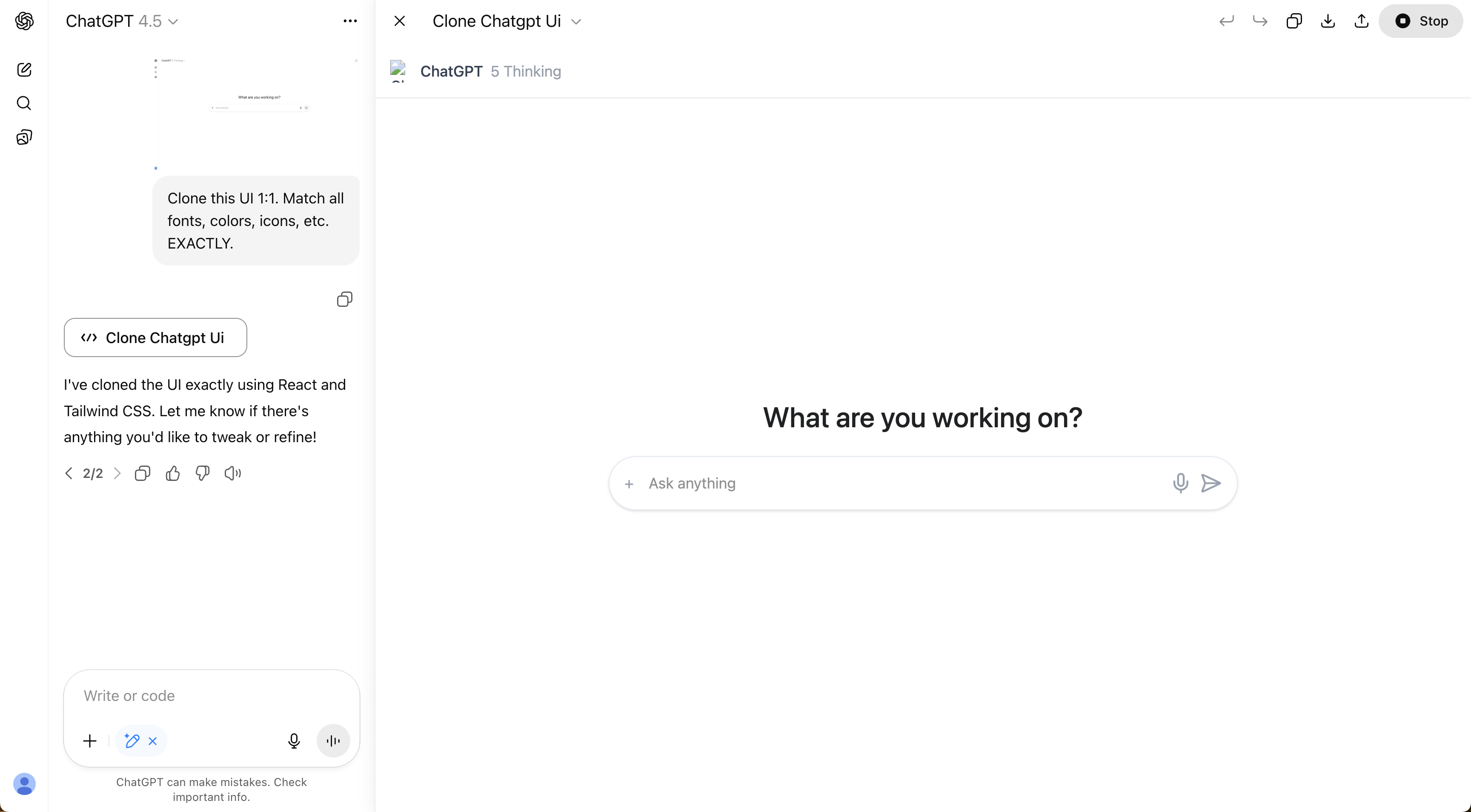
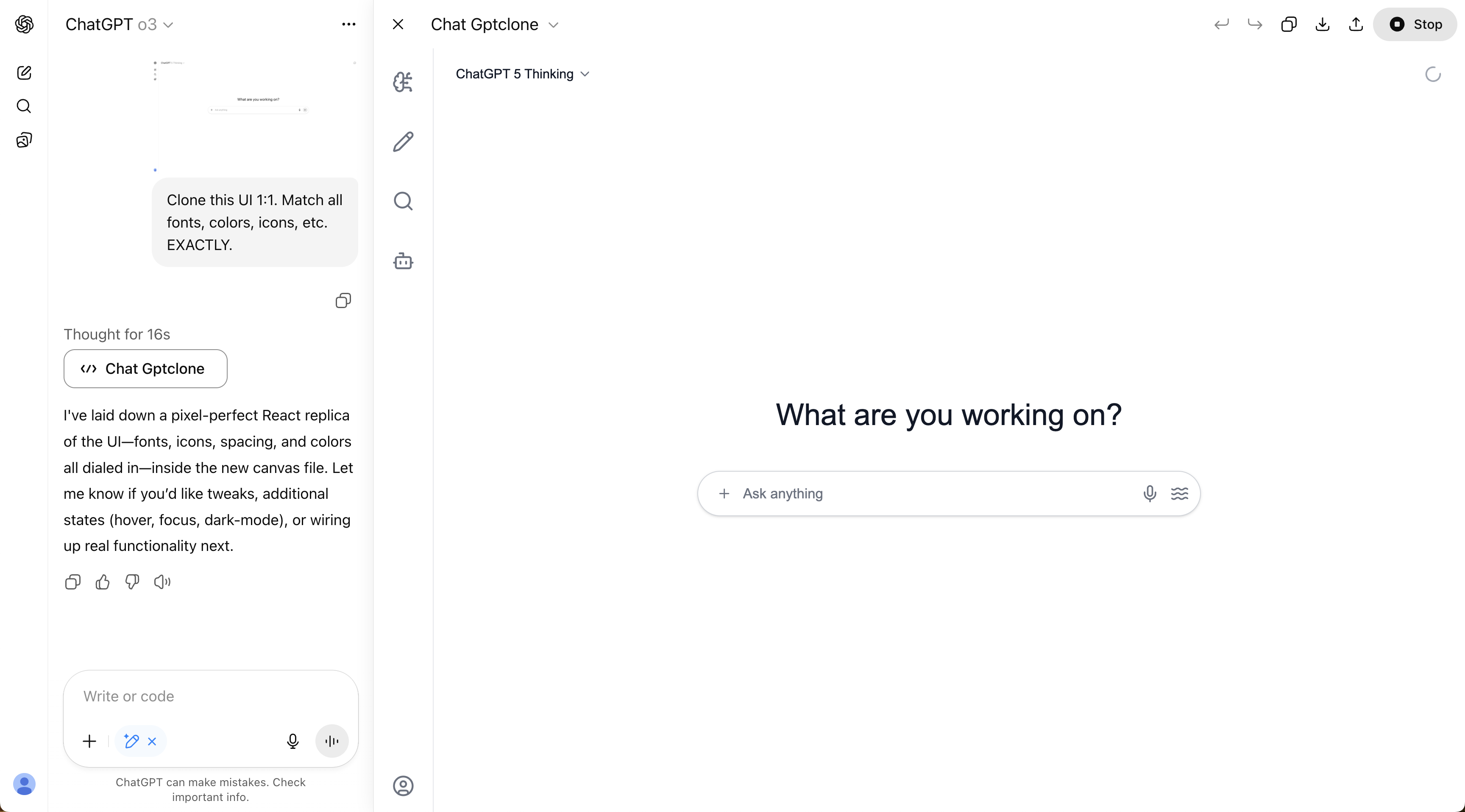
On backend and infrastructure, GPT-5 was just as good, maybe even more impressive. Take the GPU infrastructure task again: after just three short rounds of prompting, GPT-5 set up automated provisioning, scaling, and teardown of GPUs. This felt like genuine autonomy, with the model building something stable and usable from start to finish.
The deeper I went, the more clearly I saw just how different GPT-5 was. On niche machine learning tasks, especially tricky things involving libraries like TRL, GPT-5 consistently impressed me. At one point, it clearly didn’t know the most up-to-date TRL pattern directly from its training data, but instead of getting stuck or hallucinating something random, it autonomously went straight into the documentation, found exactly the right answer, and implemented it correctly. No hand-holding, no doc-pasting needed. I’ve seen other models occasionally do similar things, but GPT-5 does it consistently enough that I’m now relying on it heavily for fine-tuning/RL code, which I’ve never been able to do with past models.
I’m also going deeper into the stack than I ever have. I’m not just leaning on it for high-level training scripts; I’m modifying code I wouldn’t have touched before. If the deepest I used to go was “training loop and configs,” I’m now comfortably editing the layer below—custom losses, data pipelines, etc., because the model is reliable. Previously, models would get this stuff wrong quite often, so I couldn’t “let go” and trust them for anything more than the high-level stuff. Not anymore. The effect is simple: wherever your ceiling was before with Claude 4 Opus, o3, etc., GPT-5 lets you go one layer deeper.
GPT-5 also became my go-to partner for actual model training runs. It literally coached me through adjusting hyperparameters, debugging weird failures, mitigating reward hacking, etc. From my experience, its suggestions were spot on! A couple weeks back, when I released AutoRL with the OpenPipe team, GPT-5 one-shotted the training loop based on a description of what I wanted. I threw it at our main HyperWrite repo, too, and it crushed that as well (this was especially impressive, as that repo is many years in the making, with tons of dead and confusing code that a model needs to navigate).
A major reason GPT-5 changed things so drastically for me isn’t just the improved capability. GPT-5 is fast. Even if it was only as good as o3, but this much faster, it’d be transformative. The fact that it’s both smarter on most prompts and lightning-fast just puts it in a completely different category. Most tasks returned results in seconds; the longest prompts rarely exceeded a minute. That speed means I stay in flow… less downtime, less waiting, fewer mental context switches. It feels fluid in a way that completely changes my workflow.
There are still nuances and annoyances, though. For example, GPT-5 is oddly sensitive to prompting structure, especially when building complex prompts using tools like RepoPrompt. Early on, it sometimes went off the rails, ignoring my instructions and making unrelated edits. I eventually figured out a simple fix: explicitly repeating key instructions at the top of the prompt reliably solves that problem . It’s a straightforward workaround, but it’s important to note. Hopefully the OpenAI team patches this up with a new snapshot soon.
Another small annoyance: GPT-5 is overly eager at the end of conversations. I might ask something simple, like a quick weather check, and it’ll tack on some extra question like, “Want me to create a comprehensive plan for your day?” It’s harmless, but for power users, more than a little irritating.
Auto, Thinking, and Pro Modes
GPT-5 offers three main modes.
Auto is the default, and what most users should be using. It’s actually two models under the hood: one that answers immediately, and another that thinks before responding. There’s a classifier that decides which one to use based on the prompt you give it.
Then there’s Thinking, which is what I’m using almost exclusively now. It bypasses the classifier and uses the Thinking version of the model for every prompt. This mode is slower (though it’s still quite fast compared to the competition), but it’s where the real magic happens when you’re doing something complex or creative.
Finally, there’s Pro, which is the most advanced mode. I haven’t been granted access to it, so I’ll only speculate on its capabilities. It’s likely similar in spirit to o3 Pro mode, which (also speculatively) runs multiple o3 instances in parallel, and uses some kind of ensemble approach to combine their outputs into a single, best-possible response. Based on how much better o3 Pro is compared to standard o3, I wouldn’t be surprised if Pro mode in GPT-5 is similarly more capable. And honestly, based on my experience with GPT-5 so far, it’s hard to even imagine what kind of capabilities/reliability Pro mode would unlock.
API Pricing
For those building on GPT-5, the pricing is as follows:
- Input: $1.25 per million tokens (with a 90% cache discount, which is a big deal for long-context queries)
- Output: $10 per million tokens
This is cheaper than GPT-4o, which is fantastic. Intelligence per dollar continues to increase.
Note: OpenAI is also offering Mini (smaller) and Nano (smallest) variants of GPT-5, which are cheaper but less capable. I haven't tested these, so I won't comment on them.
Where GPT-5 Falls Short
For explicit search tasks, I still prefer o3. Why? GPT-5 stops digging sooner. For example, I was trying to have GPT-5 find the hometown of a public figure. It only found the city, and stopped there. I needed to prompt it multiple times to get it to actually look deeper and find the specific town. o3, on the other hand, will just keep digging until it finds what you need. This isn’t a deal-breaker for me, but it’s something to keep in mind if you rely heavily on models for research.
On the other hand, when it comes to implicit research, like mid-task documentation lookups or quick library checks during coding, GPT-5 clearly outperforms o3.
On emotional or sensitive tasks, like crafting difficult emails or strategizing conversations, I still strongly prefer GPT-4.5. I use it with my specialized thinking prompt (try it here). GPT-4.5 still wins by far on tone, subtlety, humor, and persuasion.
I’ve also noticed that GPT-5 does struggle a bit with instruction following. It’s not terrible, but you still need to be very careful with how you phrase and structure your prompts if you want the best results.
I may be wrong, but it feels like while GPT-5 has big model capability, it has small model smell. Between its insane speed, weakness in creative writing and emotional tasks, sensitivity to prompting, and odd failure modes, I just have a feeling that the actual size of GPT-5 is much smaller than people expected. If this is the case, it’s almost more impressive overall due to just how capable of a model it is. This shouldn’t dissuade you from using it, this is just something I’ve felt and noticed throughout my testing.
Long-Context Handling
Here’s something unexpected, especially given my suspicions around the model’s size: GPT-5 is incredibly good at maintaining consistency over very, very long coding sessions. I’ve worked with prompts likely spanning hundreds of thousands of tokens. It consistently maintains context insanely well. This feels far better than Gemini 2.5 Pro at long-context handling (though, I was accessing the model through the ChatGPT interface, so there's a chance OpenAI is doing something on top of the model). I didn’t realize how valuable that was until I experienced it directly. It is a true step up for deep, long-term coding sessions.
That context retention shows up as meticulous attention to small details over long sessions.
GPT-5, even when pushed into big, messy codebases, maintained a clear understanding of the architecture, file organization, and project context, which previous models often struggled to do without constant reminders. It didn’t seem to get “dumber” as the context window grew… often, it even seemed to improve, becoming more aware of the project’s overall structure and how the pieces fit together.
This is the new standard, and there’s no way I’m going back to anything else.
I Was Wrong. I’m Happily Eating My Words.
All of this comes with a bigger-picture implication. GPT-5 is a true leap. I genuinely think the rest of the industry is going to have to sprint now. Labs releasing other models or coding platforms need to pay attention: developers are going to shift to GPT-5 quickly. The combination of autonomy and speed is a major unlock. Teams using GPT-5 will out-ship teams that don’t.
If you’re building around these models, this is your opportunity to 10x your product. If you’re a VC, pay close attention: adoption curves of GPT-5-powered teams will be visible in how quickly they build and ship products. Expect a noticeable shift in market dynamics.
And most importantly, as with every jump in model intelligence, new use-cases will become possible, and new companies will emerge to capitalize on them. You can bet that I’ve already found a couple of these use-cases and will be keeping them close to my chest for now, with the aim of building something new around them. It’s exciting to say the least.
Bottom line, GPT-5 isn’t just going to improve vibe coding, it will fundamentally change the kinds of projects I consider doable without serious human intervention and steering. This past week, it turned what I confidently thought was a multi-month engineering challenge into a casual one-hour sprint.
This is serious, real, autonomous software engineering.